Apache Spark: aggregateByKey vs combineByKey

In this article, we will first learn about aggregateByKey in Apache Spark and in next article (to be published later as both the topics are quite big enough to be discussed in a single article), will learn about combineByKey. I will be using Java 8 for writing Spark code snippets.
Let’s first look at the signature of aggregateByKey :
aggregateByKey(V2 zeroValue, Function2<V2,V1,V2> seqFunction, Function2<V2,V2,V2> combFunction)
Basically, aggregateByKey function aggregates the values of each key with using given functions (seqFunction, combFunction) and a neutral zero value (zeroValue).
public <U> JavaPairRDD<K, U> aggregateByKey( U zeroValue,
org.apache.spark.api.java.function.Function2<U, V, U> seqFunction,
org.apache.spark.api.java.function.Function2<U, U, U> combFunction )
Use Case:
Let’s say we’ve an input RDD i,e RDD[(K, V)] and we want to group the values for K and transform to RDD[(K, U)] as an output. But you may say that we can achieve this using either groupByKey or reduceByKey but there are some known performance bottleneck with groupByKey and reduceByKey is a good alternative to it but reduceByKey doesn’t allow us to change the type of value we will be outputting. In such cases, aggregateByKey comes handy.
aggregateByKey
The aggregateByKey function requires 3 parameters:
- An initial ‘zeroValue’ value that will not effect the total values to be collected. It can be 0 if aggregation is type of sum of all values. For example if we were adding numbers the initial value would be 0. We can even have (0, 0) as zeroValue (written in Scala), in Java syntax, we can have like — Tuple2<Integer, Integer> zeroValue = new Tuple2<>(0, 0);
We may have this value as
Double.MaxValueif aggregation objective is to find minimum valueWe can also use
Double.MinValuevalue if aggregation objective is to find maximum valueOr we can also have an empty List, Map or HashSet, if we just want a respective collection as an output for each key.
2. A combining function knows as sequence function (seqFunction) accepting two parameters. The second parameter is merged into the first parameter. This function combines/merges values within a partition, i,e Sequence operation function transforms/merges data of one type [V] to another type [U].
3. A merging function knows as combining function (combFunction) accepting two parameters. In this case the parameters are merged into one. This step merges values across partitions, i,e Combination operation function merges multiple transformed types [U] to a single type [U].
Now, we have discussed enough of theoretical concepts, let’s get into the actual implementation of this concept and solve a problem statement. We are using StackOverflow dataset which can be downloaded from — https://www.kaggle.com/stackoverflow/stackoverflow?select=comments and an example record from this data set is :
<?xml version=”1.0" encoding=”utf-8"?>
<comments>
<row Id=”3" PostId=”3" Score=”2" Text=”Good naming convention and well structured code will help you decrease the comments need. Don`t forget that each line of comments you add it’s a new line to maintain!!” CreationDate=”2010–09–01T19:47:32.873" UserId=”28" ContentLicense=”CC BY-SA 2.5" />
<row Id=”5" PostId=”20" Score=”17" Text=”+1 for truth, -1 for practicality. :)” CreationDate=”2010–09–01T19:49:47.933" UserId=”9" ContentLicense=”CC BY-SA 2.5" />
<row Id=”8" PostId=”3" Score=”0" Text=”@Gabriel: that was already in my answer, look at the end.” CreationDate=”2010–09–01T19:51:45.260" UserId=”11" ContentLicense=”CC BY-SA 2.5" />
<row Id=”9" PostId=”23" Score=”2" Text=”Sometimes it’s the technique I use, but also when I’m too deep into my work and I want to change my mind to get a "fresh" look to my work.” CreationDate=”2010–09–01T19:51:48.200" UserId=”28" ContentLicense=”CC BY-SA 2.5" />
<row Id=”16" PostId=”3" Score=”1" Text=”@Lorenzo: sorry, I’ve read it and did not catch this one…” CreationDate=”2010–09–01T20:01:02.077" UserId=”28" ContentLicense=”CC BY-SA 2.5" />
<row Id=”33" PostId=”3" Score=”4" Text=”@Carson: while keeping blocks short is a well known rule, it doesn’t mean that we always can apply it.” CreationDate=”2010–09–01T20:15:59.773" UserId=”11" ContentLicense=”CC BY-SA 2.5" />
<row Id=”34" PostId=”72" Score=”12" Text=”What about copying that 3-space indented code into your tab-indented file, which you have set your tabs to 3 spaces? When you send your code to your compatriots they wonder why that function has such bad indentation!” CreationDate=”2010–09–01T20:16:23.350" UserId=”33" ContentLicense=”CC BY-SA 2.5" /></comments>
Problem : Given a list of user’s comments, determine the average comment length per hour of the day.
Solution : So, we looked upon the dataset and for this problem statement, we will use — Text & CreationDate attributes/fields only where Text is the actual comment which users give and CreationDate is the timestamp at which that particular comment has been logged and this field will be used for grouping by for our problem statement.
Let’s look at the Java 8 style Spark code :
package org.example;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.sql.SparkSession;
import scala.Tuple2;
import java.time.LocalDateTime;
import java.util.Map;
public class AggregateByKey
{
public static void main(String[] args)
{
SparkSession spark = SparkSession.builder().appName("spark").master("local[*]").getOrCreate();
JavaSparkContext jsc = new JavaSparkContext(spark.sparkContext());
JavaRDD<String> stringJavaRDDdd = jsc.textFile("D:\\backup\\Comments.xml");
JavaRDD<Map<String, String>> mapJavaRDD = stringJavaRDDdd.map(MRDPUtils::transformXmlToMap);
JavaPairRDD<String, String> javaPairRDD = mapJavaRDD.
mapToPair(pair -> new Tuple2<>(pair.get("CreationDate"), pair.get("Text")));
JavaPairRDD<Integer, String> pairRDD = javaPairRDD.filter(p -> p._1 != null && p._2 != null)
.mapToPair(tuple -> new Tuple2<>(LocalDateTime.parse(tuple._1, MRDPUtils.DATE_FORMAT).getHour(), tuple._2));
Tuple2<Integer, Integer> zeroValue = new Tuple2<>(0, 0);
JavaPairRDD<Integer, Tuple2<Integer, Integer>> aggregate = pairRDD.aggregateByKey(zeroValue, (acc, elem) -> {
{
Integer localCommentLength = acc._1 + elem.length();
Integer localCountOfTotalComments = acc._2 + 1;
return new Tuple2<>(localCommentLength, localCountOfTotalComments);
}
}, (partition1, partition2) -> {
{
return new Tuple2<>(partition1._1 + partition2._1, partition1._2 + partition2._2);
}
}
);
System.out.println(aggregate); // for debug purpose
}
}And to parse the xml file, have written a Util method for parsing the xml content :
package org.example;
import org.apache.commons.lang.StringEscapeUtils;
import java.text.SimpleDateFormat;
import java.time.format.DateTimeFormatter;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class MRDPUtils
{
private static final Pattern INTEGER = Pattern.compile("\\d+");
public static Map<String, String> transformXmlToMap(String xml) {
Map<String, String> map = new HashMap<String, String>();
try {
String[] tokens = xml.trim().substring(5, xml.trim().length() - 3).split("\"");
for (int i = 0; i < tokens.length; i += 2) {
String key = tokens[i].trim();
String val;
if (i + 1 >= tokens.length) {
val = null;
} else {
val = StringEscapeUtils.unescapeHtml(tokens[i + 1].trim());
}
map.put(key.substring(0, key.length() - 1), val);
}
} catch (StringIndexOutOfBoundsException e) {
System.err.println(xml);
}
return map;
}
public final static DateTimeFormatter DATE_FORMAT = DateTimeFormatter.ofPattern("yyyy-MM-dd'T'HH:mm:ss.SSS");
public static boolean isNullOrEmpty(String str) {
return str == null || str.length() == 0;
}
public static boolean isInteger(String str) {
if (str == null) {
return false;
}
Matcher is = INTEGER.matcher(str);
return is.matches();
}
}Output :
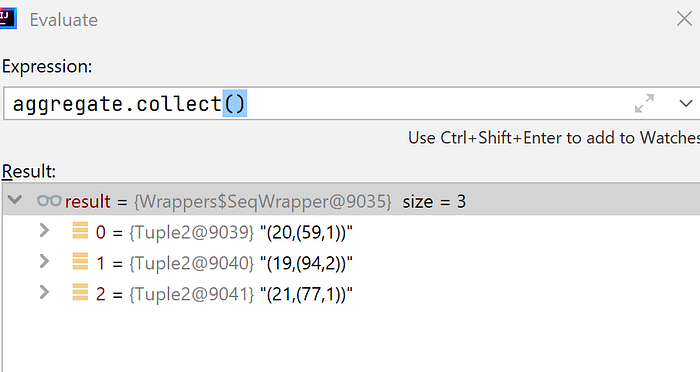
And to calculate the average, which has been left as an exercise for newbie, simply divide (tuple._2._1 / tuple._2._2).
On the Internet, most of the articles/blogs on aggregateByKey is either in Scala or Python, I couldn’t find a better one written using Java 8. My intention is to cover up for Java developers who are learning Java 8 & Spark.
